your voice, your hardware.
OpenASR is a speech-to-text app for macOS. Transcribe files, dictate into any app, and run live captions — all on your own machine. No accounts, no cloud, no telemetry.
Built to stay on your machine.
Everything runs locally by default. No accounts, no API keys, no cloud transcription path.
Stays on-device
Audio stays local by default. No accounts, no upload step, and no cloud transcription path between your files and the transcript.
privacy by architectureOpen-source runtime
Read the decoder, swap the backend, vendor it into your own product. No black boxes, no lock-in, no rug pulls.
auditable source.oasr model format
One portable file holds weights, tokenizer, and metadata. Pull it once, run it anywhere, pin it by hash. Reproducible by design.
single-file · hash-pinnedCLI + local server
One command transcribes a file. Another spins up a local, OpenAI-compatible HTTP API on localhost — drop it into any app without changing your client.
openasr serveUp and running in a minute.
The desktop app is the easiest path. The CLI is the same open-source engine, scriptable from a terminal.
- 01
Download & open
Install the signed, notarized macOS app and follow the short onboarding.
- 02
Pick a model
Onboarding suggests a recommended default — swap it any time from the Models screen, one click away.
- 03
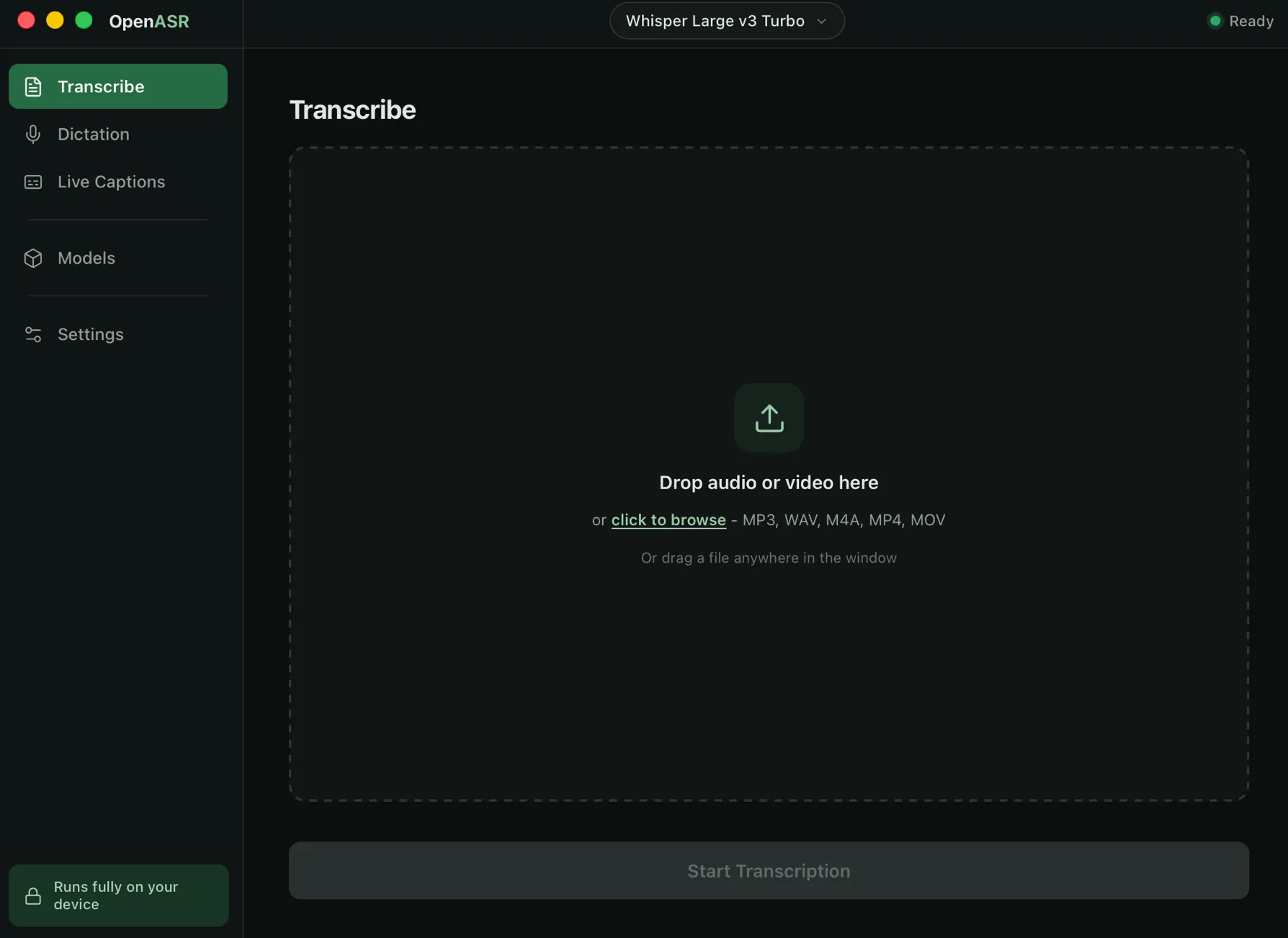
Transcribe anything
Drop in a file, dictate straight into any app, or caption system audio live — all on-device.
The desktop app is built on the open-source openasr CLI.
Grab a binary from GitHub Releases and run the whole pipeline yourself.
- 01
Pull a model
Grab a hash-pinned
.oasrbundle by name.openasr pull qwen3-asr-0.6b:q8 - 02
Transcribe a file
Subtitle-grade output next to your audio.
openasr transcribe talk.wav --srt - 03
Or serve an API
A local, OpenAI-compatible endpoint on loopback.
openasr serve
Pick a size. Pull by name.
From a 75 MB tiny model to a multilingual flagship — all in the same .oasr format.
Everything that touches your audio is open.
OpenASR is built as an open core. The entire speech pipeline that could ever touch your audio — capture, the local server, model verification, the fail-closed pull chain, and the sandbox and path checks — lives in the Apache-2.0 repository. Anyone can read it, audit it, fork it, and run transcription end to end from the CLI without us in the loop.
The macOS desktop app is a closed-source product shell over that same open core — onboarding, UI, packaging, signing, auto-update. It adds no hidden transcription path; everything that touches your audio is the open code above. If you never want the app, the CLI and open core run the whole pipeline on their own.
1 Moonshine Tiny (q8_0) measured at RTF 0.027 on an Apple M1 CPU; 37× is 1 / RTF. 2 The Whisper family covers 98 languages in the shipped model catalog.